Code Health – How easy is your code to maintain and evolve?¶
Code quality issues cost time, money, and missed deadlines. It’s vital to know when you can safely move ahead and implement new features versus when you might have to take a step back and improve what’s already there. That way, your system remains maintainable. CodeScene’s Code Health metrics lets you strike that balance:
Code Health makes code quality objective rather than subjective.
Code Health is the only code-level metric in our industry with a proven link to speed and quality.
In tandem with Hotspots, Code Health provides the quality dimension when prioritizing technical debt or looking for refactoring opportunities.
Allows you to identify by short-term risks, as well as tracking long-term trends via multiple high-level KPIs.
Fully transparent – all issues are reported in our Virtual Code Review.
Actionable: Code Health issues come with automated refactoring recommendations, and future degradations are prevented via CodeScene’s IDE integration and/or PR Quality Gates.
Why Healthy Code is a Competitive Advantage¶
Code Health is evidence-based and the effectiveness of the metric was evaluated in the Code Red paper . The Code Red paper shows that a healthy codebase enables a fast time-to-market while minimizing rework. As such, a Code Health measure complements delivery metrics like DORA:
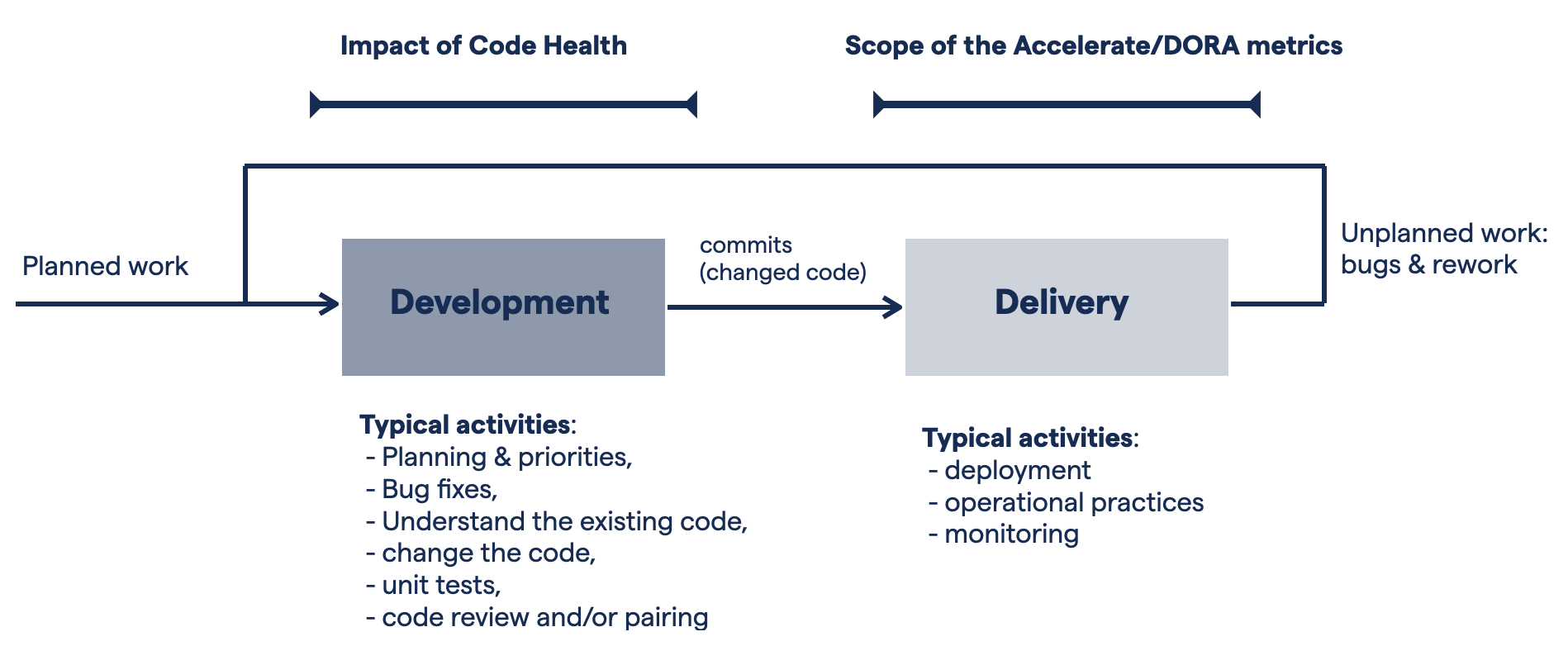
Fig. 47 CodeScene complements the DORA metrics with a similar set of measures for the code itself.¶
Measuring Code Health is a game changer – understanding the code of a large codebase has never been this easy!
Code Health identifies factors known to impact Maintenance costs and Delivery Risks¶
Code Health is an aggregated metric based on 25+ factors scanned from the source code. The code health factors correlate with increased maintenance costs and an increased risk for defects.
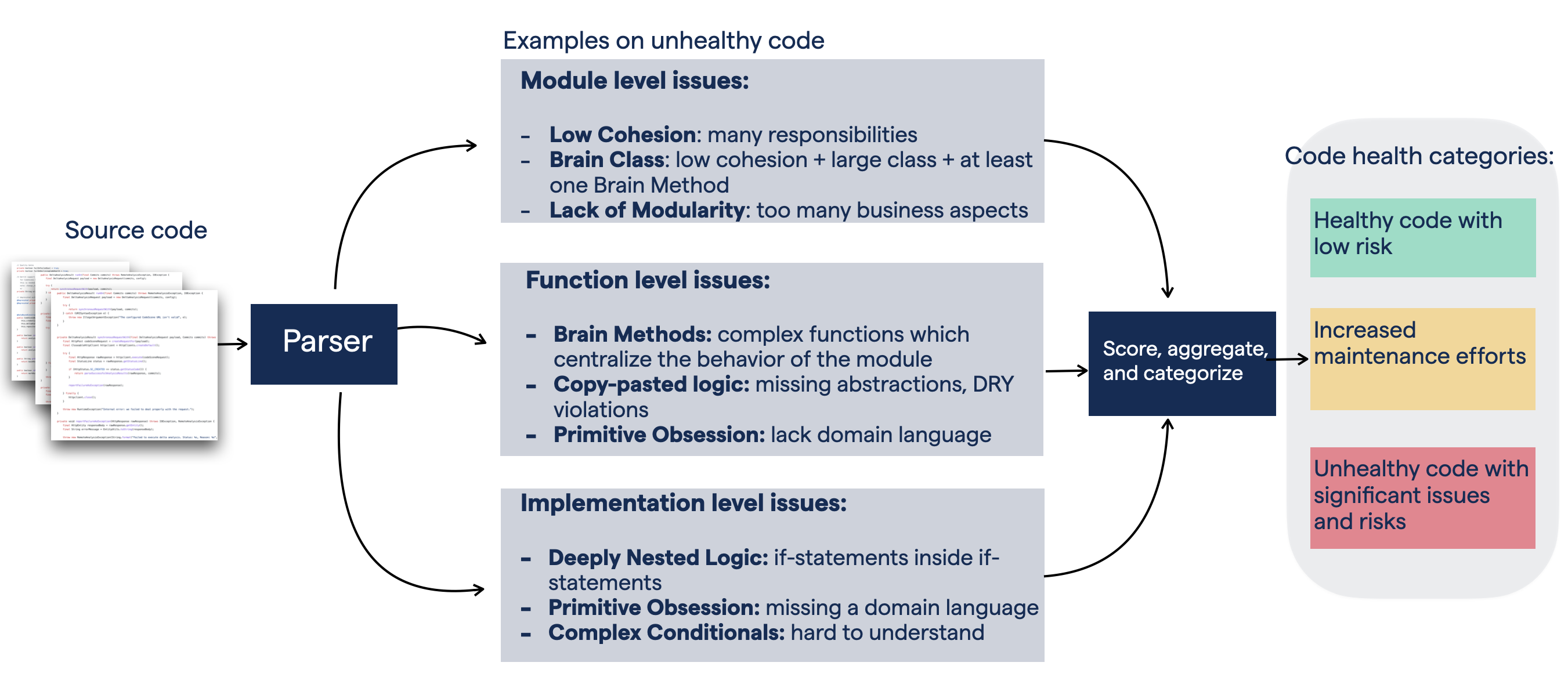
Fig. 48 The high-level concept for Code Health, an aggregated metric predicting risks and waste.¶
At the highest level, each file with source code is categorized as either Green (healthy code that’s easy to change), Yellow (complex code with maintenance issues and increased defect risk), and Red (severe maintenance issues). Examples on Code Health issues include – but are not limited to – the following:
Module Smells¶
Low Cohesion: Cohesion is calculated using the LCOM4 metric. Low cohesion means that the module/class has multiple unrelated responsibilities, doing too many things and breaking the Single Responsibility Principle.
Brain Class aka God Class: A Brain Class is a large module with too many responsibilities. A module is a Brain Class if 1) it’s a large module with many lines of code, b) it has many functions, and c) at least one Brain Method.
Developer Congestion: Code becomes a coordination bottleneck when multiple developers need to work on it in parallel.
Complex code by former contributors: If the developer behind a hotspot with low code healt leaves the organization, the maintenance risk increases significantly.
Lines of Code: Large files receive lower code health.
Function Smells¶
Brain Method aka God Function: A complex function/method that centers the behavior of the class/module and becomes a local hotspot.
DRY (Don’t Repeat Yourself) Violations: CodeScene detects duplicated logic that is actually changed together in predictable patterns.
Complex Method: Many conditional statements (e.g. if, for, while) leads to lower code health. Measured using cyclomatic complexity.
Primitive Obsession: Code that uses a high degree of built-in, primitives such as integers, strings, floats, often lacks a domain language that encapsulates the validation and semantics of function arguments.
Large Method: Large functions with many lines of code are generally harder to understand.
Implementation Smells¶
Nested Complexity: This is revealed as if-statements inside other if-statments and/or loops, and is a construct that significantly increases the risk for defects.
Bumpy Road: A bumpy road is a function that fails to encapsulate its responsibilities, leading to code containing multiple logical chunks of logic. Just like a bumpy road will slow down you driving, a bumpy road in code presents an obstacle to comprehension. There’s also an increased risk for feature entanglement. The remedy is often to extract and encapsulate the chunks of logically dispersed behaviors in their own functions.
Complex Conditional: A complex conditional is an expression inside a branch (e.g. if, for, while) which consists of multiple, logical operators such as AND/OR. This makes the code hard to understand.
Large Assertion Blocks: A test-specific code smell. Blocks of large, consecutive assert statements indicate a missing abstraction.
Duplicated Assertion Blocks: A test-specific code smell. Indicates a DRY violation as the same assertion block is copy-pasted across a test suite.
The Code Health profile and main KPIs¶
A single KPI isn’t enough to capture the multi-facetted aspect of code health in a larger codebase:
The hotspots could be healthy, but other parts of the code have severe issues.
Averages are tricky since they might hide low-scoring files that represent a risk.
Or maybe you have a problematic legacy module that is relatively stable but could be a long-term risk?
That’s why CodeScene presents two separate metrics to create a unique code health profile of your codebase:
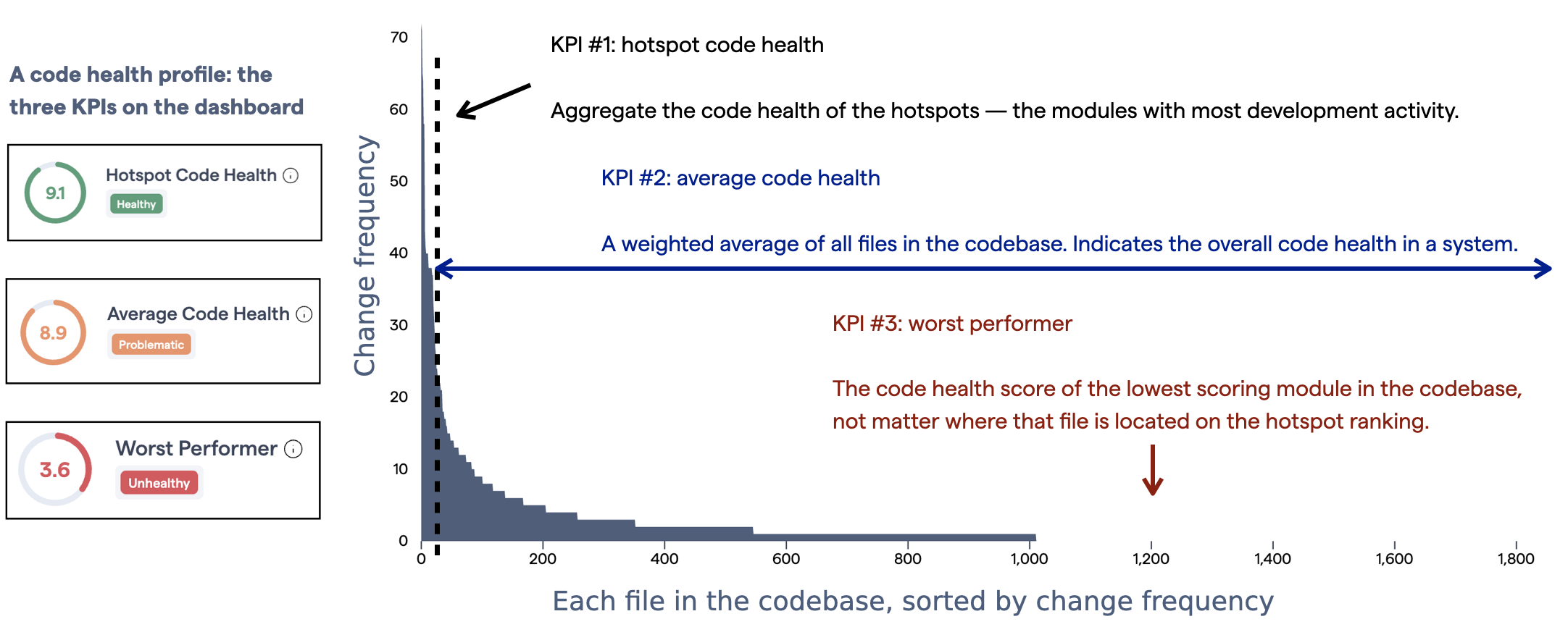
Fig. 49 The two KPIs give you a representative view of the code health.¶
The KPIs represent:
Hotspot Code Health: A weighted average of the code health in your hotspots. Generally, this is the most critical metric since low code health in a hotspot will be expensive.
Average Code Health: A weighted average of all the files in the codebase. This KPI indicates how deep any potential code health issues go. Requires that you enable the Full Scan Code Health option.
Advanced: How is the weighted average calculated?¶
The code health scores are aggregated by a weighted average. The weight is the number of lines of code (LoC) in each file. That way, a file with 5000 LoC carry more weight than a small file with 100 LoC. This provides a more accurate aggregated score. Consider:
Let’s say we have three files:
a.c: code health 2.0, LoC 5000 (a massive problem)
b.c: code health 10.0, LoC 100 (small and simple)
c.c: code health 10.0, LoC 10 (even smaller and simpler)
Calculating a pure average gives a code health of 7.33 which is high and non-representative.
However,a weighted average gives a code health of 2.18 which is much, much more representative of the codebase as a whole.
Prioritized Technical Debt¶
The Prioritized Technical Debt card provides a quick overview of high-impact technical debt in your codebase. It identifies where refactoring efforts will deliver the biggest payoff by reducing friction, waste, and risk. Unlike traditional static analysis tools that only look at the code itself, this feature considers how you work with the code - highlighting files with the highest return on investment (ROI) for refactoring.
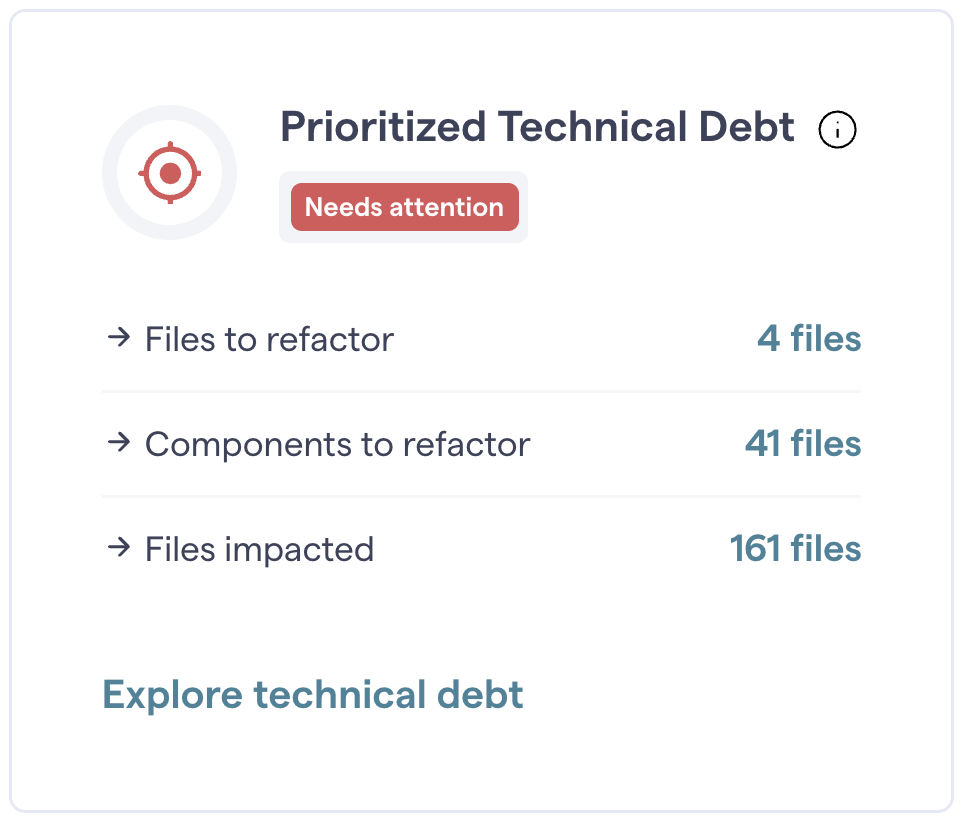
Fig. 50 The Prioritized Technical Debt card directs refactoring to where it matters most.¶
The card displays three key metrics:
Files to refactor: Files identified as having the highest priority for refactoring.
Components to refactor: Technical debt remediations identified at an architectural component level.
Files impacted: The number of files where technical debt actively impacts development. These are files where poor code quality intersects with development activity, creating friction. Addressing these files will result in the greatest immediate benefit in terms of reducing technical debt impact. These are helpful for teams owning specific parts of a larger project.
By clicking on the metrics, you’ll navigate directly to the corresponding views in the hotspot map, where you can explore the affected files in detail and plan your refactoring efforts.
Alerts: CodeScene auto-detects files that decline in Code Health¶
No matter your current Code Health level, you never want it to become worse. Once code has degraded in health, it’s expensive to bring it back on track. For that purpose, CodeScene alerts on any declining code health:

Fig. 51 CodeScene alerts on any declining code health.¶
The rules for the various alerts are:
Declining Code Health: Raised when a file shows a declining code health trend so that its score is now lower than it was over the past year. Note that we use a threshold to avoid raising alerts for minor fluctuations: the code health has to decline by at least 0.1.
Predicted Decline: Think of this as an early warning. We notify you when a file with recent development activity starts a downwards slide that is noticable, but not yet severe enough to cause a Declining Code Health alert.
File climbs on the hotspot ranking: This alerts you to a file which sees an increasing amount of development activity and is declining in Code Health. It’s a severe warning since the file is likely to become a future source of high-interest technical debt.
Improved files: CodeScene also presents positive feedback on the files that have had their code health improved. We scan all changes for the past month. Any file which improves its code health by at least 0.1 gets included on the list. Use this as an occasion to celebrate.
Adapt Code Health to your Coding Standards¶
CodeScene’s code health rules are calibrated against real-world codebases. As such, the default rules represent the state of the art when it comes to predicting maintenance and delivery risks. That said, we understand that users want a certain level of control over the code health rules. There are two options:
Code Health Directives: A directive is a source code comment instructing CodeScene to ignore a certain smell. Use directives for granular control at the function level. Described in Disable Local Smells via Code Comment Directives.
JSON config for customizations: Change the code health rules for entire repositories, folders, or files by providng a JSON file with your customizations. Described in Customize the Code Health Rules via JSON.
Disable Local Smells via Code Comment Directives¶
CodeScene lets you disable function level smells via directives provided as source code comments:
// @codescene(disable:"Complex Method")
void execute(ProgramOptions* options) {
// ...lots of complex code here...
}
The disable option instructs CodeScene to ignore the Complex Method code smell on that function. You can disable multiple code smells in the same directive:
// @codescene(disable:"Complex Method", disable:"Bumpy Road Ahead") <-- look, two disabled smells
void execute(ProgramOptions* options) {
// ...lots of complex code along a bumpy road...
}
A short cut for disabling all smells is the disable-all directive:
// @codescene(disable-all)
void execute(ProgramOptions* options) {
// ...lots of complex code along a bumpy road...
}
The code health directives have a few simple rules:
The @codescene directive supports all function smells. You cannot use them to disable file level issues (e.g. Lines of Code, Low Cohesion).
A directive always applies to the function/method following it.
Code Health directives can be part of a larger, multi-line comments (e.g. /** comment blocks */ in Java).
The string in the disable instruction has to be an exact match of the code smell name seen in the virtual code review. Unknown or misspelled directives are ignored.
The virtual code review will include a non-blocking warning informing you about the use of directives in the code together with the impact. That way, no directives fly under the radar – transparency is key.
Finally, let us share some best practices to help you get the most out of the directives:
Be restrictive with directives: the clear majority of all code health findings are real problems which should be refactored.
Make it a habit to inspect new directives: to simplify this task, CodeScene informs you about any new directives in its Pull Request review summary.
Document the rationale for introducing the directive: this helps all programmers coming after you to understand the reasons for hiding a potential code smell. That way, you can revisit the rationale and see if it still applies. The directive syntax lets you provide the rationale on the same line: // @codescene(disable-all) Rewrite next week (2020-01-30)
Customize the Code Health Rules via JSON¶
💡 Tip: There’s more info and downloadable examples in our help center
The code health rules are customized by adding a .codescene/code-health-rules.json file to your Git repositories. That way, the code health rules are persisted and version-controlled together with the application code they apply to.
CodeScene provides a template JSON file that includes documentation. You access that file via the Hotspots sections of your project’s configuration. Let’s start by looking at the configuration options:
Example on overridden code health rules
.codescene/code-health-rules.json
{
"usage" : "Persist this file inside your repositories as ...",
"rule_sets" : [ {
"matching_content_path" : "test/**",
"matching_content_path_doc" : "Specify a glob pattern relative to ...",
"rules" : [ {
"name" : "Brain Method",
"weight" : 0.5
}, {
"name" : "Large Method",
"weight" : 0.0
} ]
} ]
}
Starting from the JSON template that you get via CodeScene’s configuration view:
Remove any rules that you want to keep as-is. This prevents clutter in the config file.
Specify a weight of 0.0 to disable a rule. See “Large Method” above for an example.
Specify a lower weight for the rules you want to keep but down-prioritize. See “Brain Method” above for an example. A value of 0.5 still implies a code health hit but only at 50% of the default impact.
Commit the .codescene/code-health-rules.json file inside your repository.
Limit the customized rules to part of your code¶
The .codescene/code-health-rules.json file lets you limit the customization to a part of your codebase. This is done via glob patterns as specified by the matching_content_path field. Common examples include:
Differentiate between test and application code: Maybe you want to allow your test suites to grow slightly larger, or perhaps you want to allow a certain degree of code duplication between test methods. Specify a rule set for the pattern test/**, which means all code in a top-level test folder.
Use different rules for different programming languages: As an example, **/*.js means just JavaScript code. Other languages aren’t impacted by these overriden rules.
Note that you can have multiple rule sets – each one matching one piece of content – inside the same configuration file.
What happens to disabled rules?¶
Disabled rules are no longer be part of the code health calculation. This means the reported code health can look better than the initially reported baseline.
Disabled rules will not be presented in the virtual code review.
Disabled rules will not be supervised as part of the delta analysis and PR quality gates.
CodeScene presents a searchable summary of all overridden rules:
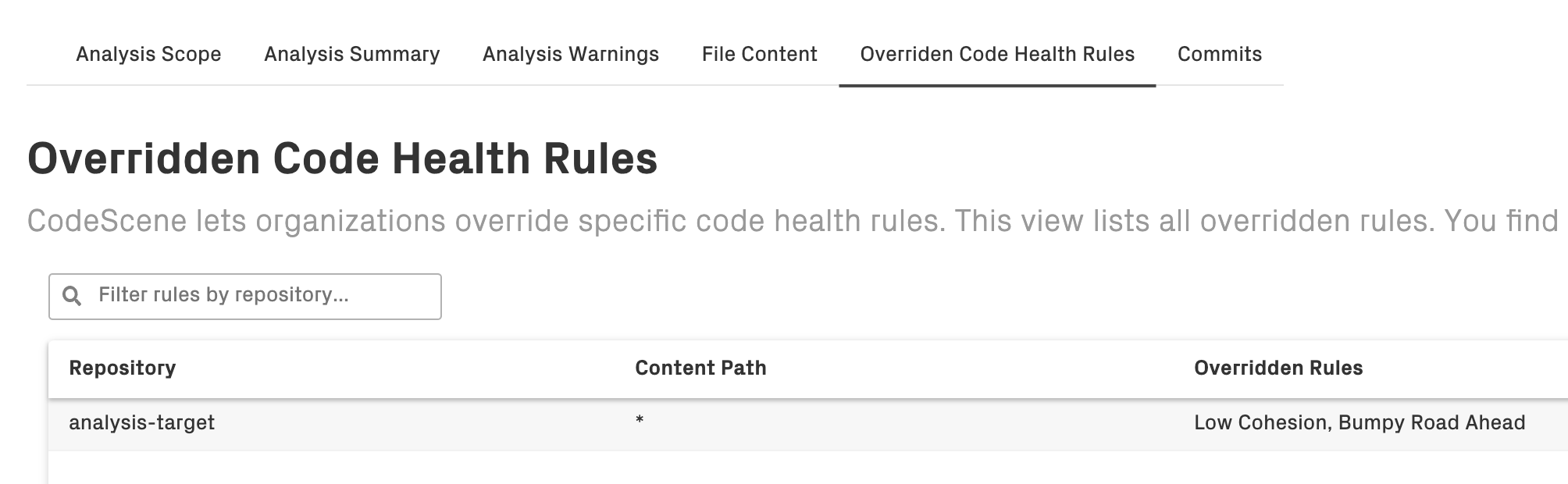
Fig. 52 CodeScene presents a searchable summary of all overridden code health rules¶
You find the preceding summary under the Scope section of each analysis.
Advanced: Override the low-level code health thresholds¶
💡 Tip: The current thresholds are documented here That link also provides complete examples on the JSON config files.
Most code health rules are compound, representing the combination of multiple code smells. For example, to report a Brain Method, CodeScene combines metrics on a) lines of code, b) cyclomatic complexity, c) deeply nested logic, and d) a centrality score. The rules above let you control the resulting, aggregated impact.
Occasionally, you might want to exert a more granular control. Perhaps you find that a cyclomatic complexity of 12 is perfectly fine in certain parts of the code. Or you want to allow multiple, large assertion blocks in specific test suites. Disabling the complete rule would be too invasive as you risk missing out on critical findings. But don’t worry – we have you covered.
CodeScene allows you to override a sub-set of the code health issue thresholds. You find a list of the supported overrides in the code-health-rules.json template discussed above. Specify a numeric value for the thresholds you want to change, and commit the rules to your repo as discussed previously; it’s the same JSON configuration file for thresholds as for the rules.
Example on overridden low-level thresholds in
.codescene/code-health-rules.json
{
"usage" : "Persist this file inside your repositories as ...",
"rule_sets" : [ {
"matching_content_path" : "test/**",
"matching_content_path_doc" : "Specify a glob pattern relative to ...",
"rules" : [],
"thresholds" : [ {
"name" : "function_cyclomatic_complexity_warning",
"value" : 10
}, {
"name" : "function_nesting_depth_warning",
"value" : 3
}
} ]
}
Any thresholds you override will be presented in the virtual code review of each impacted file. That way, you have full transparency into the impact.
Advanced: use multiple rule sets and global code health rules¶
CodeScene lets you point out one specific repository – via the project configuration – that serves as the source for global rules. These global rules will apply across all Git repos in your project. Typically, the global rules are used to reflect organization wide coding rules.
The global rules are overridden by .codescene/code-health-rules.json inside each repository. Hence, the hierarchy is:
Local rules inside a repository have the highest precedence.
The global rules specified in your project configuration has the second precedence.
If none of those rules match, we use CodeScene’s defaults, meaning maximum relative weight for each rule.
The global rules are set by providing the name of the repository in the “Repository with global code health rules” field of the project configuration. This field is located in the “Hotspots” tab of the project configuration.
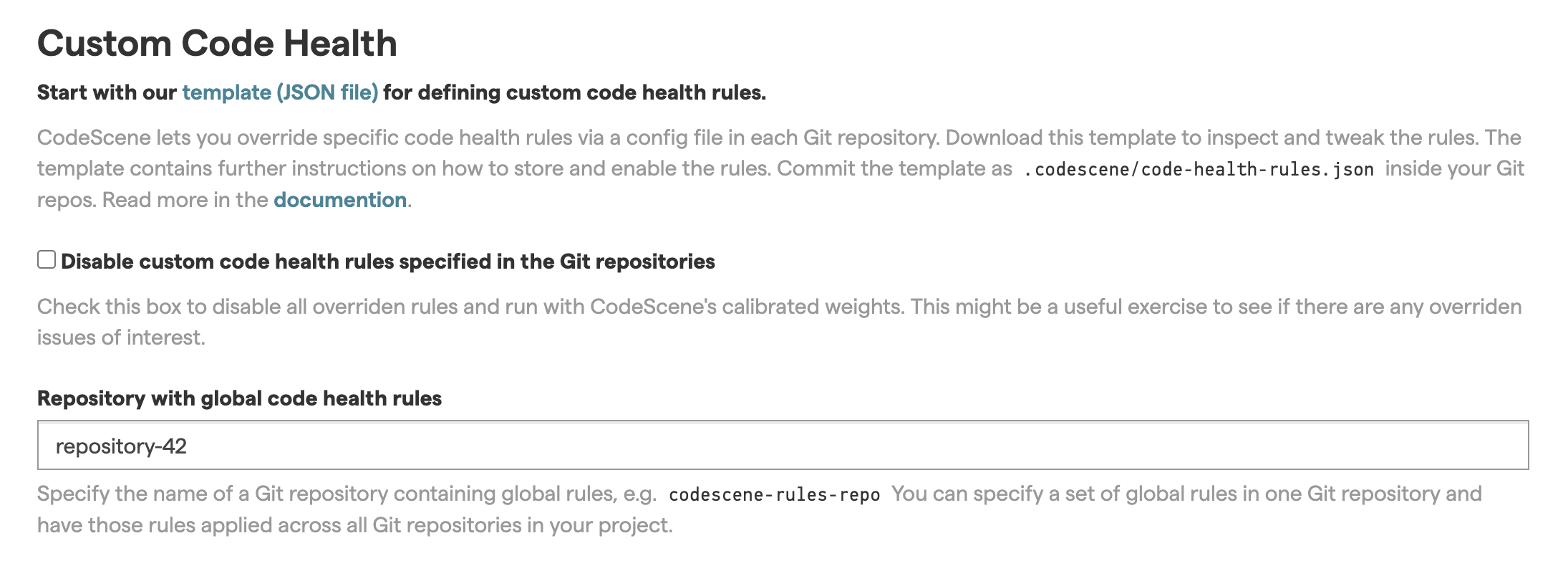
Fig. 53 Identify the repository containing the global code health rules by indicating its name here.¶
Note that:
The repository containing the global rules must also be one of the repositories contained in the project. In other words, it needs to be visible in the “General > Repository” list.
The delta analysis uses the global rules that were present during the last full analysis. This means that when updating global rules, a full analysis has to be performed before they apply to delta analyses.
Recommendations for customizing code health rules¶
Our recommendations for customizing the code health rules:
Never disable the critical rules: The individual code health metrics come in two categories: 1) critical rules and 2) advisory. While the advisory rules might be at odds with your internal coding standards, the critical rules are hard to argue against. Disabling rules might mean that you miss an opportunity to act early on potential problems.
Auto-Detect Declining Code Health with the PR Integration¶
A code health decline can be expensive to reverse. To prevent it, integrate CodeScene in your Pull Requests: Integrate Automated Code Health Reviews in Pull Requests and Merge Requests.