Project Configuration¶
Specify the Git Repository to Analyze¶
Select the repository or repositories you want to analyze in your project.
There’s a recent trend towards organizing the source code of larger systems in multiple Git repositories. For example, you may have the code for your user interface in one repository, the code for your service layer in another repository and perhaps even a Git repository dedicated to your back end mechanism. Another typical example is Microservices where each service is deployed according to its own life cycle. In that case, organizations often chose to use one Git repository per service.
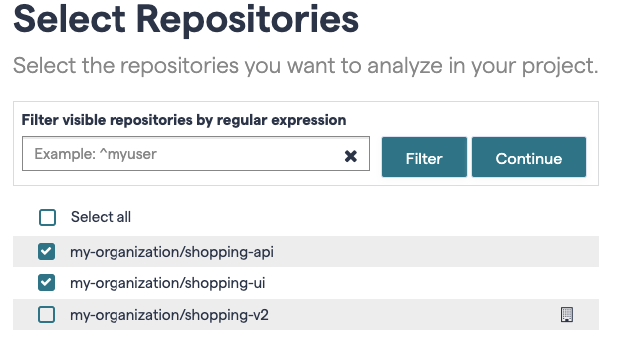
CodeScene supports an analysis of multiple repositories at once.
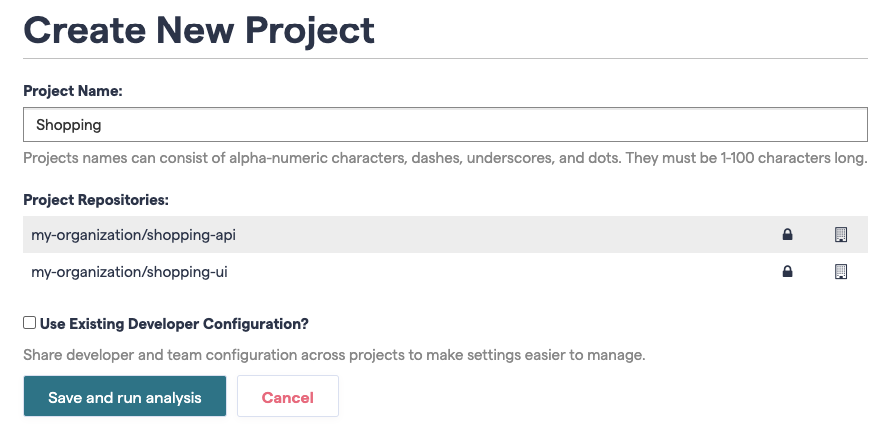
Fig. 207 Configuration of multiple repositories.¶
The screenshot above shows two repositories that belong to the same product. During an analysis, CodeScene will analyze the evolution of the code in all those repositories as though they were in the same physical Git repository.
You can specify as many repositories as you want and remove one at any time. However, a word of warning: do NOT attempt to analyze unrelated repositories in the same configuration. First of all it’s a breach of the license agreement. Worse, you won’t get useful results since many of the basic metrics, like Hotspots, are relative metrics.
Measure Change Coupling across Multiple Repositories¶
The normal change coupling metric considers two files coupled if they tend to change in the same commits. This won’t work if your codebase is split across multiple repositories. Instead, you want to aggregate individual commits into logical commits. CodeScene supports two different strategies for aggregating commits:
- By Author and Time
When you specify this option, the tool will consider all commits by the same author on the same day as a single, logical commit. This option is a heuristic that works well in the absence of a Ticket ID in your data.
- By custom Ticket ID
This option uses an identifier in your commit headers. All commits that refer to the same identifier will be considered one logical commit.
The second option, By custom Ticket ID, is the preferred method. Fig. 208 shows the options in the repository configuration section Change Coupling.

Fig. 208 There are two available strategies for aggregating commits.¶
To aggregate by custom Ticket ID, you need specify a Ticket ID Pattern, in
the Ticket ID Mapping section (see Fig. 209). The pattern
is used to extract the Ticket ID from the commit message. The example pattern
in Fig. 209 will extract all identifiers that start with the
text ISSUE- followed by at least one digit. For example, the commit
message ISSUE-42 will result in 42 as the extracted Ticket ID.
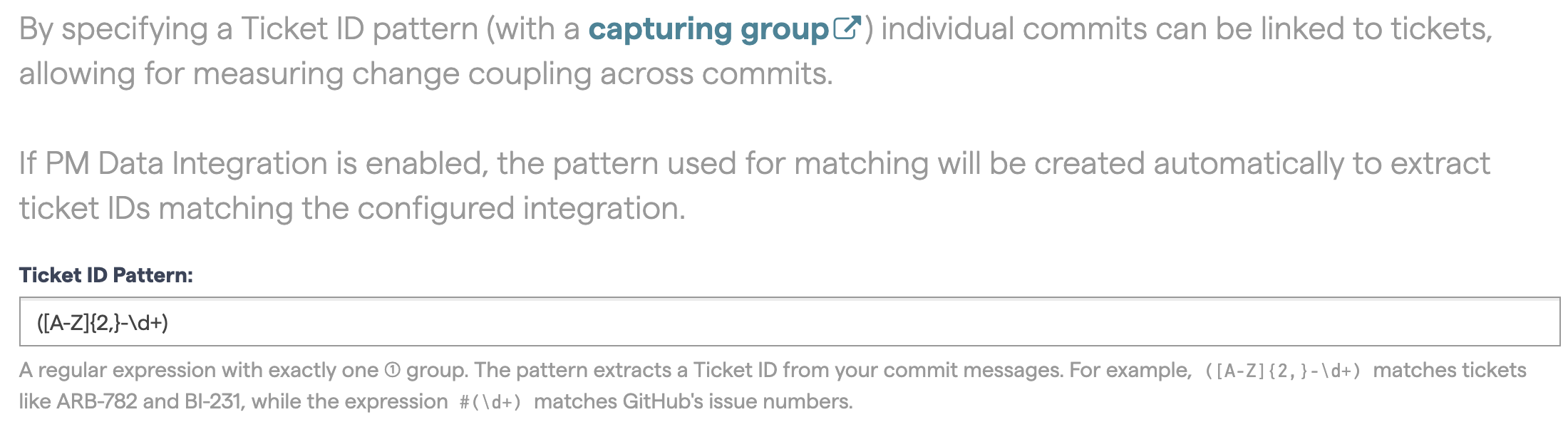
Fig. 209 Configure a pattern to extract a Ticket ID.¶
Note that CodeScene will still calculate normal change coupling on a single commit basis. You want that in order to spot unexpected dependencies between files in the same repository. The change coupling results for the logical commits discussed above are presented in a separate analysis view.
Change Coupling Exclusion Filters¶
You might have files that you expect to be temporally coupled, for example tests and the corresponding units under test, or matching .c and .h files. To exclude these coupling from visualization by default, go to the “Change Coupling” section of the project configuration and add “Change Coupling Filters” for the patterns you want to exclude, as shown in Fig. 210.

Fig. 210 Configure change coupling filters for expected file couplings.¶
Each filter has a name, that can be anything you like, and patterns for coupled file paths. The patterns are a regular expressions. When a pair of coupled files match the patterns, in either direction, they are excluded by the filter.
All filters are tried in sequence, and if any filter hits a coupled pair, the pair is excluded. Some useful examples of patterns are:
Pattern (File 1) |
Pattern (File 2) |
Description |
|---|---|---|
|
|
C/C++ includes, e.g. |
|
|
Java “Impl” pairs, e.g. |
|
|
C# interface pairs, e.g. |
|
|
Python files and tests, e.g. |
If any of the patterns have capturing groups, both matches must generate the same number of captures, with equal values, to trigger the filter. Note that non-capturing groups and negative look-ahead in regular expressions can be useful if you want to write advanced filters, and only trigger filters on corresponding files in corresponding directories.
Linking to an External Ticket System¶
If you have a Ticket ID Pattern configured, and a way to deep-link to tickets by the matched identifiers, you can configure a Ticket URI Template to enable links in analysis views. That way you will be able to quickly navigate from Code Churn by Task to the external ticket system, and view more details there.
The Ticket URI Template is based on the URI Template format (RFC
1) , with support for the single
expression {ticket-id}. The matched ticket value, i.e. the captured value
of the regular expression group, is used as {ticket-id} for hyperlinks.
For example, if your Ticket ID Pattern is #(\d+), and your Ticket URI
Template is https://example.com/tickets/{ticket-id}, a commit containing
the string #1234 will result in a hyperlink to
https://example.com/tickets/1234.
Some useful examples of Ticket ID Patterns and Ticket Template URIs are:
JIRA:
(\[A-Z]{2,}-\d+)andhttps://example.com/jira/browse/{ticket-id}Azure DevOps:
#(\d+)andhttps://dev.azure.com/your-org/your-project/_workitems/edit/{ticket-id}
Detect Patterns in Code Comments¶
Exhaustive use of certain code comments indicate code smells. For example, a file that is filled with TODO comments is usually not that reassuring. On a similar notes, organizations might use static analysis tools and use code comments to suppress the findings. By configuring a set of patterns, you can use CodeScene’s virtual code reviewer to detect such patterns as shown in Fig. 211.
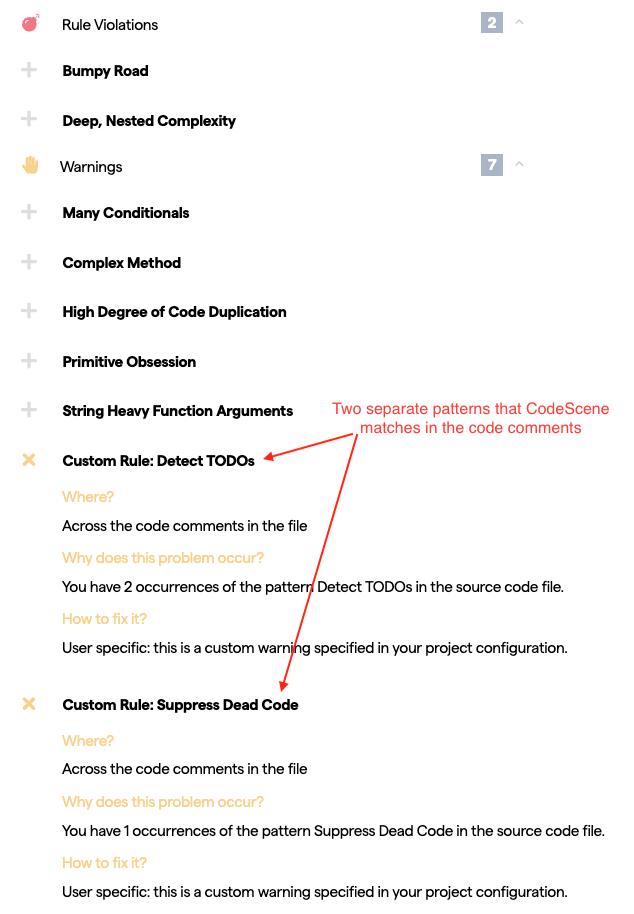
Fig. 211 Detect specific type of code comments.¶
The configuration is a bit special, but read along for examples – it’s not hard:

Fig. 212 Configure regular expressions to detect code comments.¶
Fig. 212 presents two patterns that CodeScene will match in the code comments of your hotspots. Each pattern consists of two parts, separated by the regex inline comment syntax, (?#comment):
A regular expression to match in the code comments.
A descriptive name of the content that the regular expression matches. This will be used in the virtual code reviewer.
In the first example, we match the expression codechecker_w+. That is, any code comment that starts with codechecker_ followed by a string such as _confirmed or _critical. We then add the descriptive comment (?#Suppress Dead Code). Note that only “Suppress Dead Code” makes up the name; the (?#…) syntax is only to embed the name in the regex.
The second example shows a simpler pattern where we match the literal string TODO in a code comment, and associate it with the label “Detect TODOs” which will then be displayed in the virtual code review.
Exclude Initial Commits from an Analysis¶
Some Git repositories start their life as an import of an existing codebase. If the previous history isn’t migrated together with the code, the author that does the initial commit of the existing codebase gets all the credit. This leads to a bias in the social analyses.
The solution is to exclude all contributions done as part of the initial commit. You specify those commits (fetch them from your Git log) in the project configuration as shown in Fig. 213.
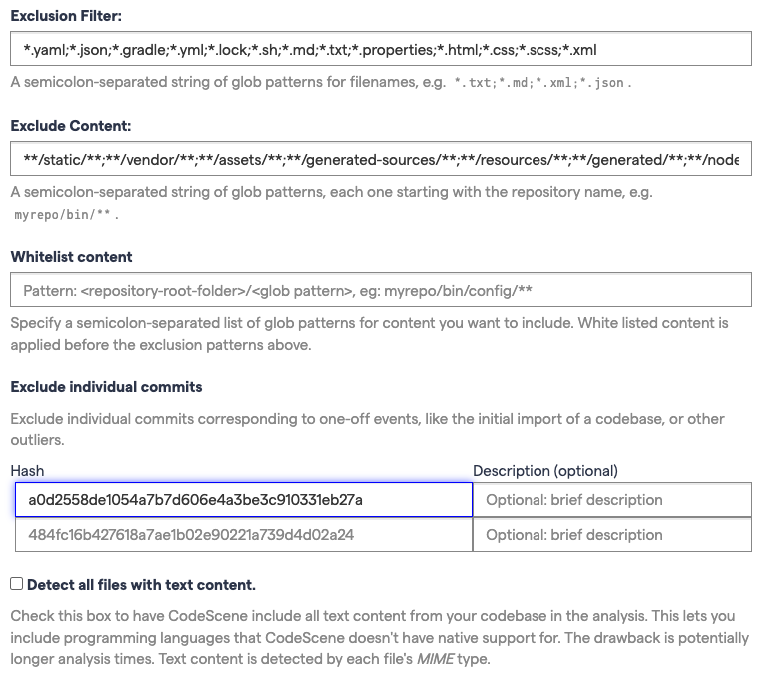
Fig. 213 Exclude specific commits from the analysis.¶
Exclude Files from an Analysis¶
An analysis will include all textual content in your repository. That means: you get an analysis of your build scripts, resource files, configuration files, test data, etc. While it’s a good practice to run an analysis of all content every now and then, there’s also the risk that you get too much noise in the analysis results. For example, you typically want to exclude auto generated content.
The Exclude Files option lets you specify a set of file extensions that will be excluded from your analysis:

Fig. 214 Exclude specific types of files.¶
CodeScene comes with a set of pre-defined exclusion patterns that should match the most common cases. You’re free to extend this set if you have additional file types that you want to exclude. Just remember to use a semi-colon (;) to separate each file extension you want to exclude.
Exclude Specific Files and Folders from an Analysis¶
You just learned how you can exclude certain types of files, no matter where they are located in the your codebase. But sometimes you’d like to exclude a particular file or, more often, a complete folder. For example, let’s say that you check-in third party code in your repository. You don’t want that code to obscure potential analysis findings in your own code.
There are two different ways to exclude complete folders and files:
Whitelist the content you want to include in the analysis. All other content will automatically be excluded.
“Exclude Content” that isn’t of interest in the analysis, typically 3rd party code and auto-generated code.
You can specify both white- and black list content. The white listing will be applied first.
You specify a glob pattern to white list the content to include in your analysis as illustrated in Fig. 215.

Fig. 215 Glob patterns to whitelist content.¶
You specify a glob pattern to Exclude Content from the analysis as illustrated in Fig. 216.

Fig. 216 Glob patterns to exclude content.¶
The example above will exclude all content under the external folder and the file samples.txt from the generator folder.
Note: You need to specify your exclusion paths using UNIX style path names. That is, use forward slashes as separators. Also note that the paths have to start with the name of your repository root. That is, if your Git repository is located in a folder named backend, as in the example above, you have to prepend that folder name to all your exclusion patterns. The reason for that is due to CodeScene’s support for multiple repositories where you have to be explicit about what repository you exclude things from.
There’s one exception to the rule that patterns have to specify the repository root. That’s the case when you want a pattern to apply across all repositories. For example, let’s say that you want to exclude all shell scripts in your test folder. In that case you specify a pattern like **/test/*.sh That is, your patterns are allowed to start with a wildcard too.
A Brief Guide to Glob Patterns¶
Glob patterns let you specify paths- and file names with different wildcards. CodeScene supports the following wildcards:
*: A single asterisk matches any string of characters. Use it to exclude or while list particular files. For example *.h will exclude all files with extension h. You can also use the single asterisk to specify glob patterns that apply to all your repositories in a multi repository analysis project. For example, the glob pattern */version.txt will match (and possibly exclude) the version.txt files at the top level of each of your repositories.
**: The double asterisk matches whole paths/directories. You use the double asterisk to exclude or white list content independent of the content’s location in your codebase. For example, the pattern myrepository/**/*.h will match all files with extension h in any directory in your repository. You can also use the double asterisk to match exclude or white list whole folders. Let’s say we want to exclude all our unit tests from an analysis and that those tests are located in the repository ‘coolstuff’. Here’s a pattern for that: coolstuff/test/**.
?: The question mark matches a single character.
Please note that all glob patterns are specified using UNIX style path names. That is, if you’re on Windows you do not use backslash to separate directory names, but rather the UNIX style forward slash. That is, the directory SomeRepo\Test is excluded by specifying SomeRepo/Test/**.